Description
Machine reading comprehension (MRC), a task which asks machine to read a given context then answer questions based on its understanding, is considered one of the key problems in artificial intelligence and has significant interest from both academic and industry. Over the past few years, great progress has been made in this field, thanks to various end-to-end trained neural models and high quality datasets with large amount of examples proposed.
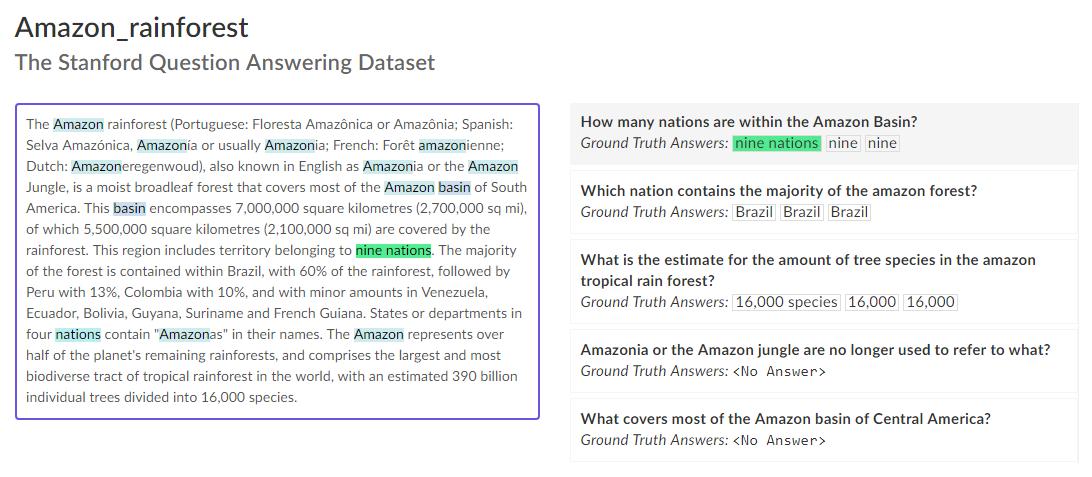 Figure 1: MRC example from SQuAD 2.0 dev set
Figure 1: MRC example from SQuAD 2.0 dev set
DataSet
- SQuAD is a reading comprehension dataset, consisting of questions posed by crowd-workers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
- GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
Experiment
QANet
QANet is a MRC architecture proposed by Google Brain, which does not require recurrent networks: Its encoder consists exclusively of convolution and self-attention, where convolution models local interactions and self-attention models global interactions.
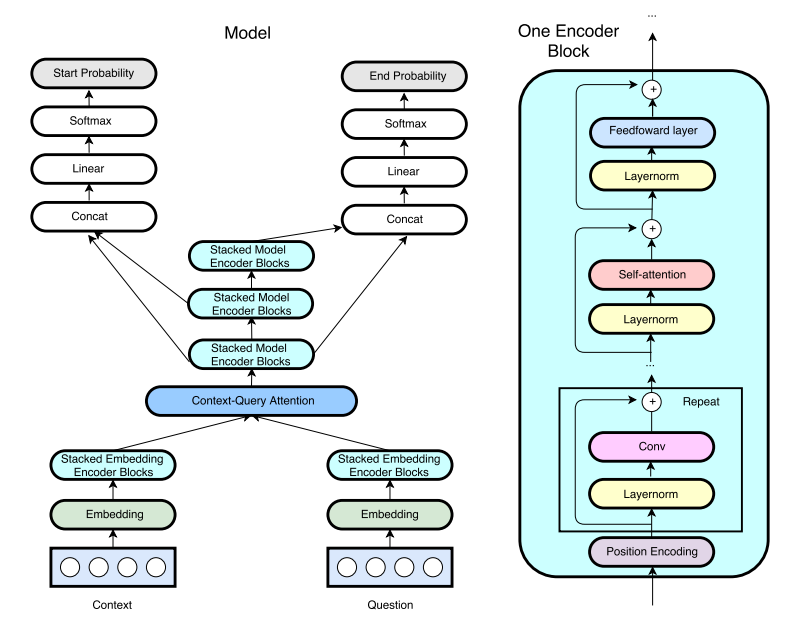
Figure 2: An overview of the QANet architecture
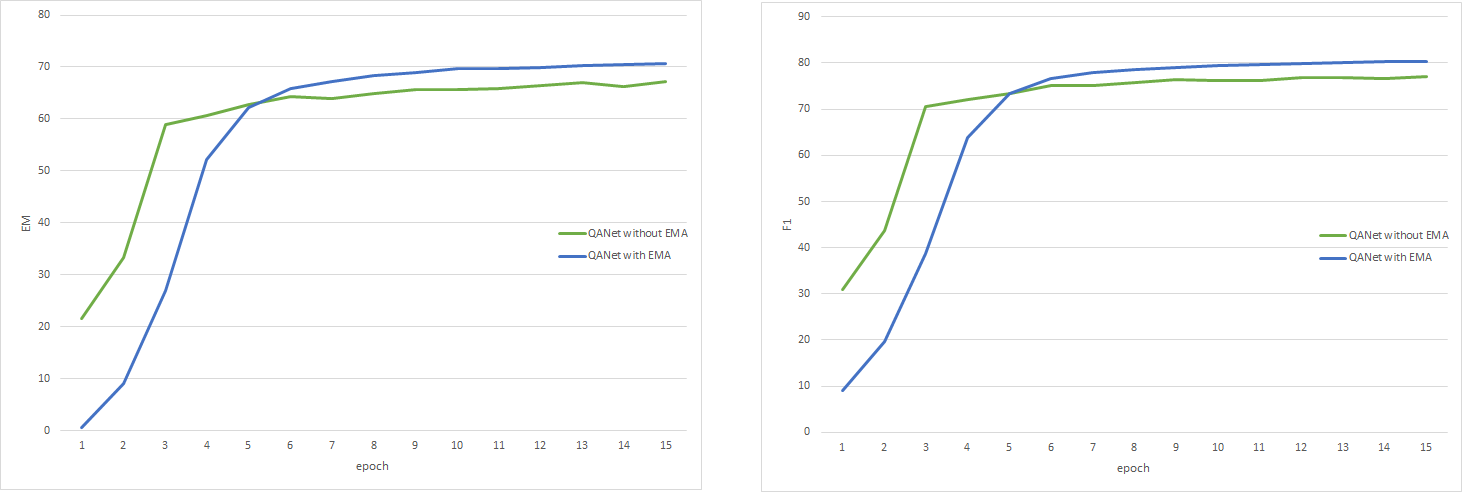
Figure 3: The experiment details are reported on SQuAD v1 dataset. Both train & dev sets are processed using Spacy. Invalid samples are removed from both train & dev sets. EM results for QANet model with/without EMA are shown on left. F1 results for QANet model with/without EMA are shown on right
| Model | # Epoch | # Train Steps | Batch Size | Data Size | # Head | # Dim | EM | F1 |
|---|---|---|---|---|---|---|---|---|
| This implementation | 13 | ~70,000 | 16 | 87k (no aug) | 8 | 128 | 70.2 | 80.0 |
| Original Paper | ~13 | 35,000 | 32 | 87k (no aug) | 8 | 128 | N/A | 77.0 |
| Original Paper | ~55 | 150,000 | 32 | 87k (no aug) | 8 | 128 | 73.6 | 82.7 |
Table 1: The performance results are reported on SQuAD v1 dataset. Both train & dev sets are processed using Spacy. Invalid samples are removed from train set only. Settings for this QANet implementation is selected to be comparable with settings in original paper
BiDAF
BiDAF (Bi-Directional Attention Flow) is a MRC architecture proposed by Allen Institute for Artificial Intelligence (AI2), which consists a multi-stage hierarchical process that represents the context at different levels of granularity and uses bidirectional attention flow mechanism to obtain a query-aware context representation without early summarization.
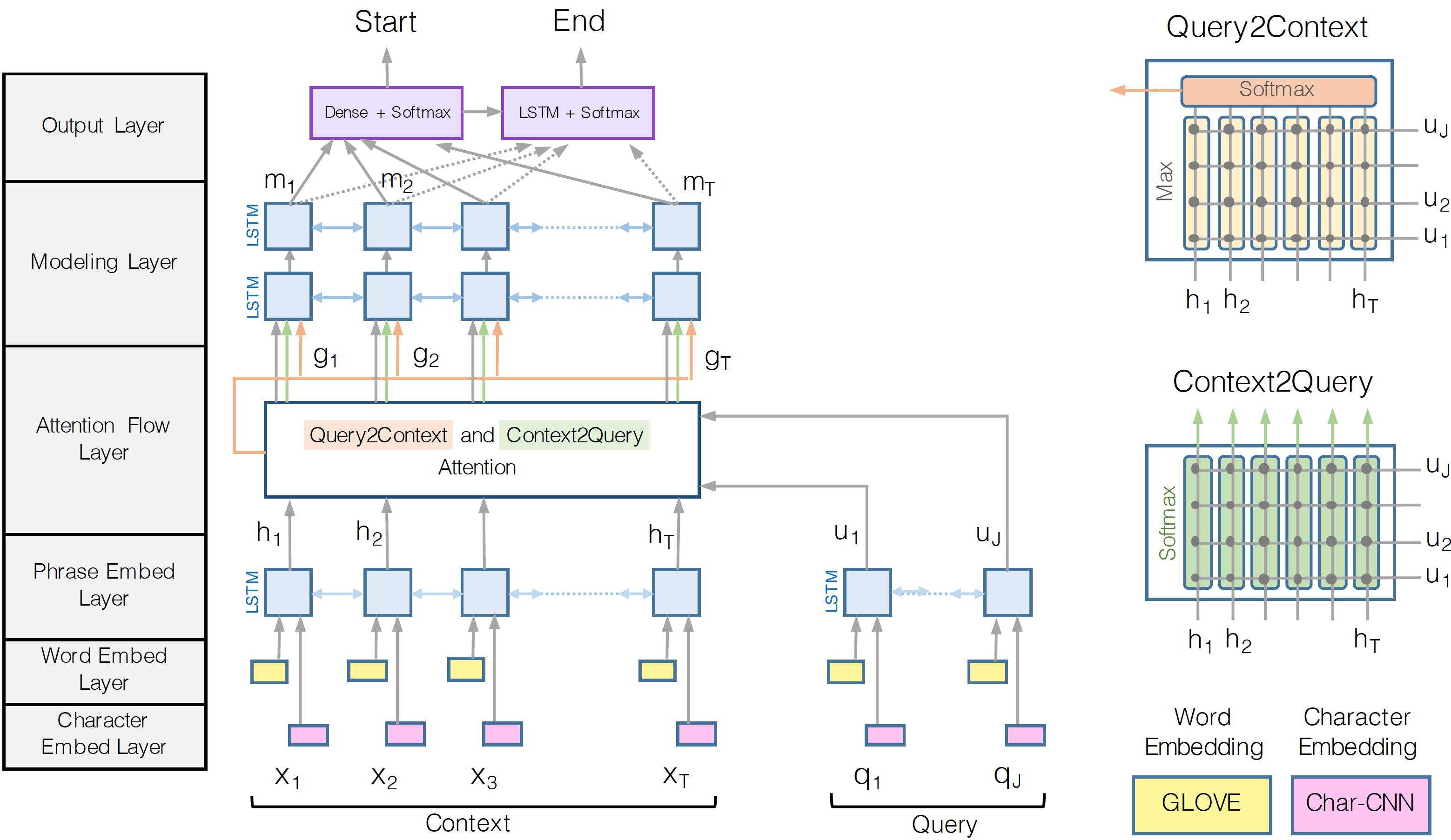
Figure 4: An overview of the BiDAF architecture
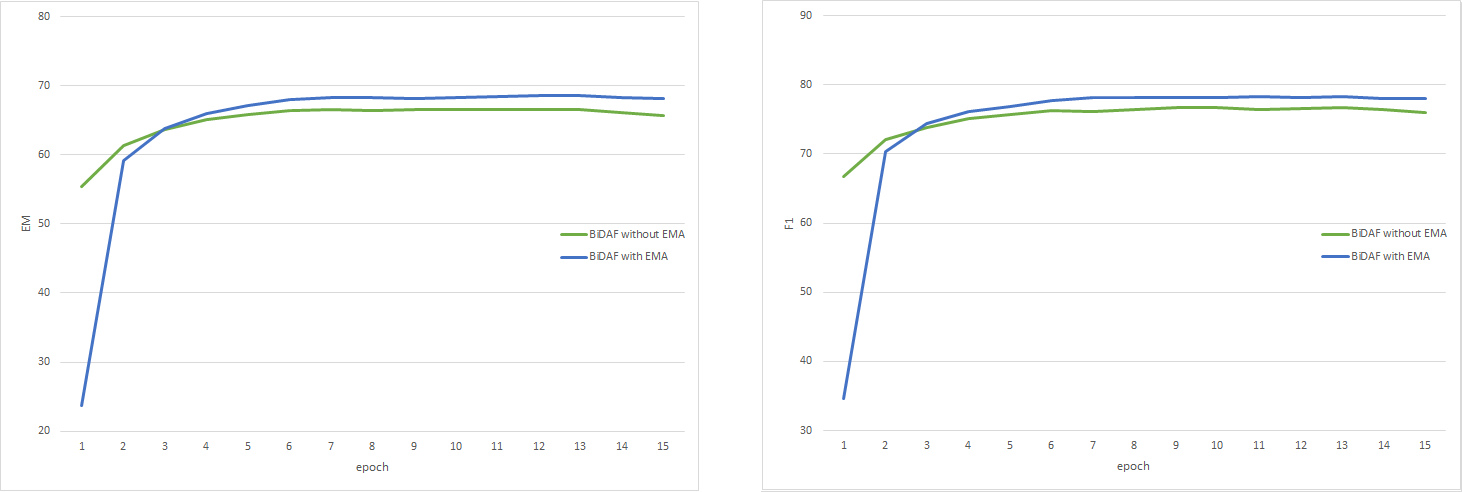
Figure 5: The experiment details are reported on SQuAD v1 dataset. Both train & dev sets are processed using Spacy. Invalid samples are removed from both train & dev sets. EM results for BiDAF model with/without EMA are shown on left. F1 results for BiDAF model with/without EMA are shown on right
| Model | # Epoch | # Train Steps | Batch Size | Attention Type | # Dim | EM | F1 |
|---|---|---|---|---|---|---|---|
| This implementation | 12 | ~17,500 | 60 | trilinear | 100 | 68.5 | 78.2 |
| Original Paper | 12 | ~17,500 | 60 | trilinear | 100 | 67.7 | 77.3 |
Table 2: The performance results are reported on SQuAD v1 dataset. Both train & dev sets are processed using Spacy. Invalid samples are removed from train set only. Settings for this BiDAF implementation is selected to be comparable with settings in original paper</i>
R-Net
R-Net is a MRC architecture proposed by Microsoft Research Asia (MSRA), which first matches the question and passage with gated attention-based recurrent networks to obtain the question-aware passage representation, then uses a self-matching attention mechanism to refine the representation by matching the passage against itself, and finally employs the pointer networks to locate the positions of answers from the passages.
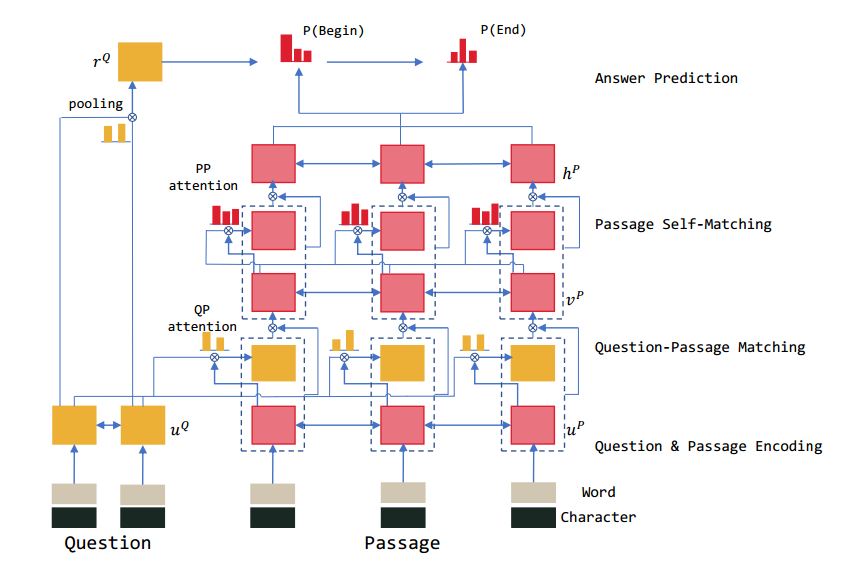
Figure 6: An overview of the R-Net architecture</i>
Reference
- Adams Wei Yu, David Dohan, Minh-Thang Luong, Rui Zhao, Kai Chen, Mohammad Norouzi, and Quoc V Le. QANet: Combining local convolution with global self-attention for reading comprehension [2018]
- Min Joon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. Bidirectional attention flow for machine comprehension [2017]
- Wenhui Wang, Nan Yang, Furu Wei, Baobao Chang, and Ming Zhou. Gated self-matching networks for reading comprehension and question answering [2017]
- Danqi Chen. Neural reading comprehension and beyond [2018]